
सांख्यिकी आणि मशीन लर्निंग - भाग २ - शंभर?
मागच्या भागात मी दोन प्रारूपं (मॉडेलं) दाखवली. सांख्यिकी पद्धतीनं प्रारूप बनवलं तर त्रुटी (error) आली १.८८, आणि मशीन लर्निंग वापरलं तर त्रुटी आली ०. कुठलं प्रारूप निवडायचं, ह्यात त्रुटी शून्य असेल तर ते प्रारूप कधीही निवडू नये. त्यातून सरसकटीकरण (generalisation) करता येत नाही. सगळी विदा रटल्यामुळे त्रुटी शून्य आली आहे.
त्यामुळे ह्या भागात मशीन लर्निंगसाठी प्रारूपात काहीसा बदल केला आहे. आणि ३०च्या जागी १०० विदाबिंदू निवडले तर काय दिसेल?
हे सांख्यिकी प्रारूप; आणि त्याची त्रुटी आहे - २.२८
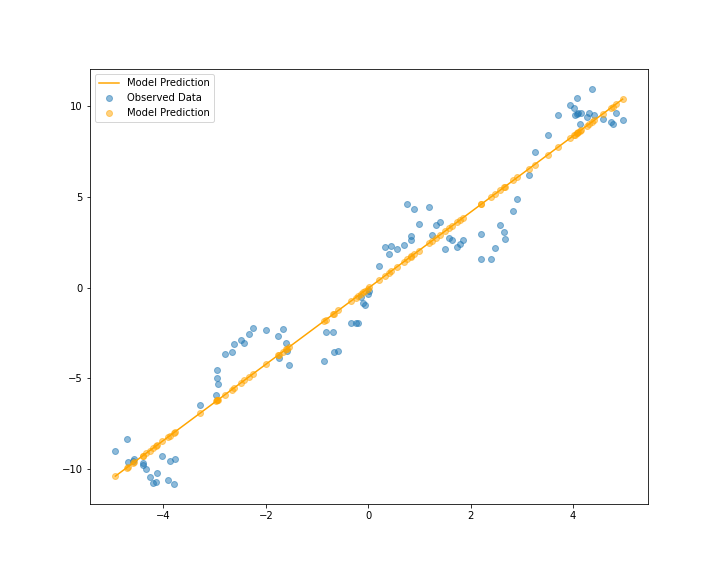
आता १०० विदाबिंदू मिळाल्यानंतर सांख्यिकी प्रारूप चुकीचं आहे हेही दिसायला लागलं आहे. मशीन लर्निंग मॉडेलमध्ये थोडा बदल करून ते कसं दिसतंय पाहा -
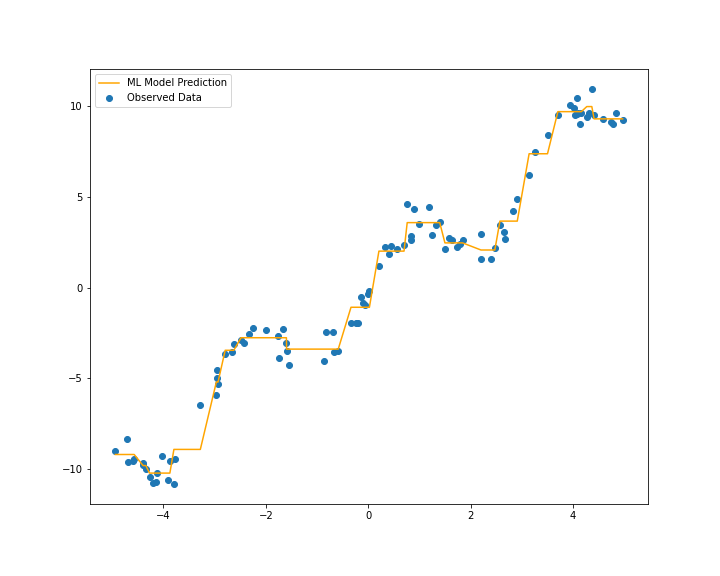
ह्यातली त्रुटी आहे ०.४ हे आलेख बघून मशीन लर्निंग मॉडेल जास्त उपयुक्त आणि ग्राह्य आहे, हे दिसतंय. शिवाय मशीन लर्निंग मॉडेल दिलेल्या विदेबाहेरच्या विदेसाठीही उपयुक्त ठरेल असं हा आलेख बघून दिसत आहे.
शिवाय १०० विदाबिंदू मिळाल्यावर सरळ रेषेचं सांख्यिकी प्रारूप योग्य आहे असंही वाटत नाही. ही विदा तयार करण्यासाठी वापरलेलं समीकरण होतं
f(x) = x + 2 * sin(2x) + gaussian_noise
हे समीकरण काय आहे, ते समजल्यावर फार गुंतागुंतीचं नाही. मात्र पुरेशी विदा नसेल, तर ते मूळ समीकरण काय आहे, हे आलेख/आकृत्या काढूनही समजणार नाही. शिवाय ते समीकरण काय आहे हे लक्षात आल्यानंतर प्रारूप बदलावं लागेल. ह्याउलट मशीन लर्निंगचं प्रारूप मूळ समीकरणाचं स्वरूप समजल्याशिवाय बऱ्यापैकी भाकीतं करू शकतं.
प्रत्यक्षात मॉडेलं बनवताना अशी समीकरणं लिहिणं बहुतेकदा शक्य नसतं. तरीही मशीन लर्निंगची प्रारूपं सहजरीत्या वापरता येतात; पुरेशी विदा असेल तर योग्य भाकितं करता येतात. कुठलीही गृहितकं न धरता, फक्त पूर्ण विदा असेल तर ती मॉडेलं बऱ्यापैकी विश्वासार्ह भाकितं करू शकतात.
भाकीतच, पण निराळं
समीकरणाचं भाकीत करणं निराळं आणि X माहीत असेल तर y चं भाकीत करणं निराळं. बहुतेकदा गरज दुसऱ्या प्रकारची असते. X माहीत असतो, y चं हवं असतं.
एका माणसामुळे किती लोकांना करोना विषाणूची लागण होऊ शकते ह्याचं समीकरण लिहिण्याची गरज नसते; तो आकडा मिळवणं महत्त्वाचं असतं. त्यावर पुढची भाकितं आणि त्यातून धोरणं ठरवायला मदत होते.
अरे बापरे!
"अरे बापरे!" हा उद्गार अगदी बरोबर आहे. हे 'हिडन लेयर' प्रकरण म्हणजे एक भुताटकी आहे.
म्हणूनच, मशीन लर्निंग, रीइन्फोर्स्ड लर्निंग हे प्रकार जोवर फॉर्मल मेथड्सनी सिद्ध होत नाहीत तोवर त्यांच्यावर विसंबून रहाणे धोक्याचे आहे.
(असे माझे अगदीच 'डमीज' मत आहे.)
ह्यात काहीही भुताटकी नाही, अजिबातच नाही.
ह्यात हिडन लेयर वगैरे काही नाहीत. हे साधं डिसिजन ट्री आहे; ह्यात हिडन लेयर नसतातच. ह्यात काय सुरू आहे हे सगळं सहज समजून घेता येतं. ते समीकरण म्हणून मांडता येत नाही एवढाच काय तो फरक आहे.
(आता मला मराठीत लिहिता येणार नाही, त्यामुळे इंग्लिश)
Decision tree is one of the simplest machine learning algorithms; it can explained fully (well almost fully). Neural networks have hidden layers. A lot of new methods have come up that can explain even the hidden layers, especially when it comes to images. Reinforcement learning is a completely different set of models, where one can trace every single step of learning.
Machine learning models do a fantastic job at fitting to non-linear response. In here, I have used a linear statistical model and it is doing poorly, compared to its ML counterpart. I could have used a non-linear model, say used some Fourier component and the model would do good again. But that means I have to change the model, altogether. An ML model can easily adapt to non-linearity in the data.
Where ML 'loses' to statistical models, generally if not always, is the explanability to extreme. Here I have used only one dimensional X for explaining. Mostly we get X as a vector of many dimensions; 10-50-100 ... then interaction of those dimensions is not easy to explain with ML models. Statistical models are relatively easier to explain.
जिथे मॉडेल समजावून सांगणं महत्त्वाचं असतं, आणि दोन-चार फीचर्स असतात तिथे न्यूरल नेटवर्क आणि त्याच्या हिडन लेयर्स वगैरे वापरणं म्हणजे डास मारण्यासाठी (तोफ नाही तरी) बंदूक आणणं होईल.
काही प्रश्न.
मला Statistics, AI, ML मधलं काही माहित नाही. मला शिकायची सुरुवात करायची आहे. त्यामुळे विचारलेले प्रश्न काहीच्या काही वाटू शकतात. थोडं सांगितलं तर मदत होईल.
१) production environment मधे २०००+ databases आहेत. प्रत्येक database चे ६००+ tables आहेत. मी दर महिन्याचा सगळ्या database चा metadata (म्हणजे कोणत्या table मध्ये किती rows आहेत) गोळा करतो - मागच्या २० महिन्यांपासून.
वेगवेगळ्या database च्या client चा application usage वेगवेगळा आहे. मला असं बघायचं असलं की किती client एखादं feature जास्त वापरतात आणि म्हणून काही set of tables चा data growth जास्त आहे आणि उरलेल्या clients चा काही वेगळा pattern आहे application usage चा म्हणून त्यांचे काही वेगळे set of tables जास्त वापरात आहेत. असं काही करता येतं का थोड्या सोप्या पद्धतीने Statistics, AI, ML वापरून? हे manually करणं अवघड आहे.
२) production चे IIS logs माझ्याकडे आहेत. ते पण १८ महिन्यांचे आणि चार वेगवेगळ्या regions चे आहेत. मी त्यांचं दर तासाचं (म्हणजे hourly) aggregation करून database मध्ये ठेवू शकतो. database मध्ये store करण्याचं काम एक-दोन महिन्यांत होणार आहे. aggregated data मधल्या URLs, त्यांची response size, time taken ह्यांचा वापर करून काही patterns automatically शोधता येतील का - जसं response size काही URLs साठी वाढत जातंय किंवा वर्षाच्या कोणत्या वेळेत application usage जास्त असतो आणि तो कोणत्या clients चा.
३) पुस्तकं/ यू ट्यूब व्हिडीओ - नवीन शिकतांना चांगल्या पुस्तकांच्या / व्हिडीओ च्या लिंका असतील तर.
मला जमतील तितपत उत्तरं.
सांख्यिकी शिकण्यासाठी खान अकॅडमी एक नंबर आहे. अगदी प्राथमिक ते मूलभूत संकल्पना फारच सोप्या प्रकारे सांगितल्या आहेत. मशीन लर्निंगच्या सुरुवातीसाठी Andrew Ng on Coursera. (ह्याच्या आडनावाचा उच्चार कसा करतात?)
ही मॉडेलं बनवली जातात त्यात कसलं तरी भाकीत करायचं असतं. आहे त्या विदेतून अर्थ लावण्यासाठी सांख्यिकीच उपयुक्त. फक्त पॅटर्न बघायचा असेल तर साधे नियम, समीकरण-छाप काही उपयुक्त असतं. तुमचं उदाहरण वाढवून पाहते -
मला असं बघायचं असलं की किती client एखादं feature जास्त वापरतात आणि म्हणून काही set of tables चा data growth जास्त आहे आणि उरलेल्या clients चा काही वेगळा pattern आहे application usage चा म्हणून त्यांचे काही वेगळे set of tables जास्त वापरात आहेत.
हा प्रश्न असा मांडता येईल - किती वापर वाढला तर किती जागा लागेल; त्यासाठी किती स्रोत (रिसोर्सेस) वापरावे लागतील. त्याची तयारी ठेवावी लागेल? वापर कशामुळे वाढतो ह्याची काही मॉडेलं असतील, ती कदाचित तुमच्या परीघात असतील किंवा नसतील.
पण वापर कोणत्या घटकांमुळे वाढतो, कमी होतो; विदागारं कधी कमी पडतात; बँडविड्थ किंवा बाकी देखभाल कमी पडल्यामुळे कधी गोष्टी मोडतात; त्याचा वापराशी संबंध काय; अशा प्रकारचे प्रश्न मॉडेलं बनवून सोडवता येतील. हे प्रश्न मी काम करत्ये त्या एका प्रकल्पासारखे आहेत. आज जाहिरातींवर किती खर्च केला तर चार-सहा महिन्यांनी किती घरं विकली जातील आणि त्यातून किती नफा मिळेल. म्हणजे चार-सहा महिन्यांनी १ कोटी रुपये हवे असतील तर आज किती खर्च करायचे? त्यामुळे तुमच्यासाठी कदाचित हे प्रश्न अगदी निरुपयोगीही असतील... माझ्याकडे तंत्रज्ञानाबद्दल मूलगामी आकलन नाही.
पुढच्या भागात इथलं सांख्यिकी मॉडेल निरुपयोगी का आहे, हे लिहिण्याचा प्रयत्न करणार आहे. त्यात कदाचित सांख्यिकीच्या काही मूलभूत संकल्पनांशी परिचय होईल.
शिवाय मशीन लर्निंग मॉडेल
का बरं त्या मॉडेलचे समीकरण प्रेडिक्टेबल नाहीच्चे मग सँम्पलबाहेरच्या विदेकरता प्रेडिक्ट काय व कसं करणार?