
सांख्यिकी आणि मशीन लर्निंग - भाग १ - तीस
सांख्यिकी (statistics) विरुद्ध मशीन लर्निंग अशा प्रकारची चर्चा आमच्या ऑफिसात नेहमीची असते. हल्लीच त्यावर दोघांनी मिळून एक भाषण दिलं. त्यात त्यांनी वापरलेली पद्धत इथे वापरली आहे.
ही लेखमाला लिहिण्यासाठी निमित्त झाले आपले सर्वांचे किंवा काहींचे लाडके अण्णा तथा अबापट. त्यांनी मला खाजगीत लिहिलं, "म्हणजे तुम्ही रागावणार नसलात तर (आणि तरच) एक विनंती करायची होती." करोना-कोव्हिडसंदर्भांतली सांख्यिकी प्रारूपं - statstical models - अण्णांना अंधश्रद्धा वाटतात. हे शब्द अण्णांचे नाहीत; अण्णा पॅसिव्ह (अग्रेसिव्ह) छापातले असल्यामुळे ते हे शब्द वापरणार नाहीत. पण मथितार्थ तोच. मग मीही त्यांना काही पॅसिव्ह अग्रेसिव्ह उत्तर दिलं. चारचौघांत ते उत्तर लिहिणं शक्य नाही. त्यामुळे नवा लेख लिहिण्यावाचून मला गत्यंतर नाही. शहाणे करून सोडावे, लेख वाचणारे जन.
दुसरं, परवा गविंना प्रश्न पडला होता, रशियाच्या लशीबद्दल एवढे विवाद का आहेत? तर त्या लशीचा वेगवेगळ्या माणसांवर कसा परिणाम होतो, ह्याचं समीकरण आपल्याला माहीत नाही. आहे त्या विदेच्या तुकड्यांतून आपल्याला पूर्ण चित्र बनवायचं आहे. त्यात मी असं काहीतरी म्हणाले, "तीस विदाबिंदू असले तर काही निष्कर्ष काढता येतो, असं संख्याशास्त्रात समजलं जातं. पण तीसच का, ह्याचं उत्तर मला माहीत नाही." म्हणून मी माझ्या परीनं ते समजून घेण्याचा प्रयत्न करत आहे.
ह्या लेखमालेत सांख्यिकी आणि मशीन लर्निंग प्रारूपं, मॉडेलं कशी चालतात ह्याचा आढावा घेणार आहे. प्रत्यक्ष करोनाची लागण, रोगप्रसार आटोक्यात आणण्यासाठी कुठली प्रारूपं वापरतात, ह्याची माहिती आणि आकलन मला नाही. पण सर्वसाधारणपणे गोष्टी कशा चालतात ते बघू. तरीही उदाहरण म्हणून करोनाचा उल्लेख लेखमालेत अधूनमधून आल्यास ती फक्त ललित प्रकारची उपमा असेल; वैज्ञानिक माहिती नाही.
---
समजा, आपल्याकडे काही विदाबिंदू, data-points आहेत. ते कसे असतात? तर गणित, भौतिक वा सांख्यिकीमध्ये y = f(x) अशा प्रकारची साधी समीकरणं तुम्ही बघितली असतील. समजा आलेख काढला तर क्ष किंवा X अक्षावरच्या ठरावीक बिंदूसाठी य किंवा y किती असेल ह्याचं चित्र म्हणजे असा काहीसा आलेख.
समजा आपल्याकडे तिसाचा वानवळा (sample) आहे. ठरावीक 'क्ष'साठी 'य' किती ह्याची तीस उदाहरणं आपल्याकडे आहेत. आणि ते असं दिसतंय.
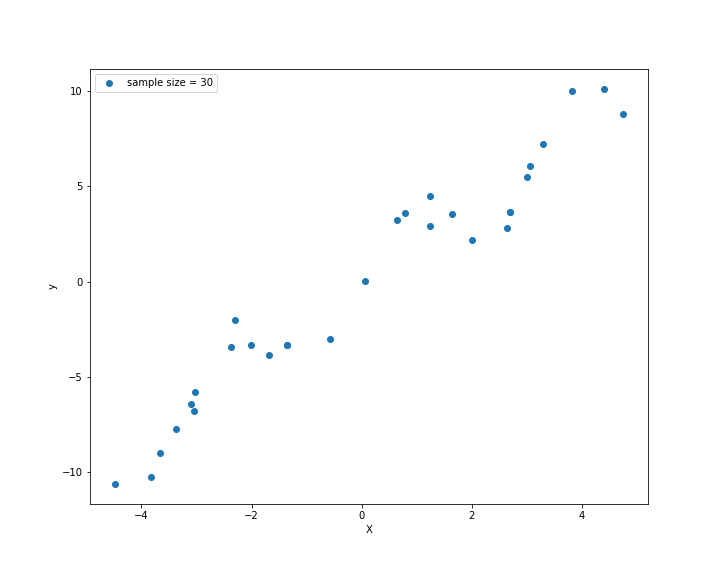
वरच्या आलेखात आडव्या क्ष अक्षाच्या सीमा उणे पाच ते अधिक पाच (-५ ते +५) अशा आहेत. त्यांतल्या विवक्षित बिंदूना य अक्षाची किंमत काय ते मांडलेलं आहे.
वानवळा किंवा sample म्हणजे काय? तर संपूर्ण विदा किंवा समुदायातले (population) मोजके बिंदू. संपूर्ण समुदाय कसा दिसतो, कसा आहे ह्याचं कमीतकमी शब्दांतलं वर्णन म्हणजे y = f(x). ह्यांतलं f(x)चं नक्की स्वरूप आपल्याला माहीत नाही. त्याचं सगळ्यात सोपं उदाहरण म्हणजे सरळ रेघ. गणिती भाषेत : y = mx + c
वरची आकृती बघितली तर मी त्याला सरळ रेघेचे प्रारूपच चिकटवेन. ते असं दिसेल -
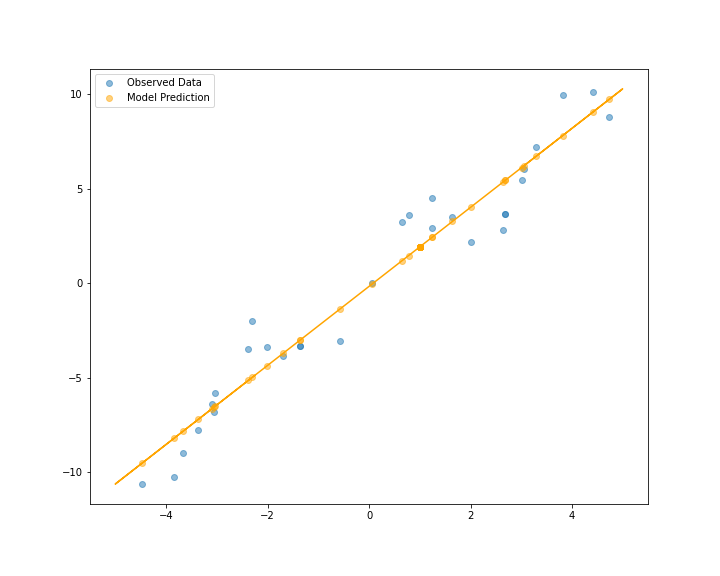
हे एक प्रकारचं सांख्यिकी प्रारूप झालं. ह्याला मशीन लर्निंग म्हणता येणार नाही. कारण विदा बघून मी f(x)चं स्वरूप कसं असेल ह्याचा अंदाज बांधला आणि मग त्याचं प्रारूप बनवलं. ह्यात xच्या किंमतीनुसार y किंमत कशी बदलेल ह्याचं गणित मांडलं. म्हणून हे झालं सांख्यिकी प्रारूप. ह्या प्रारूपाची त्रुटी आहे साधारण १.८८, किंवा २ पेक्षा थोडी कमी. (त्रुटी किंवा error कशी मोजतात, वगैरे गोष्टी ह्या लेखमालेच्या कक्षेबाहेर आहेत. सांख्यिकी आणि मशीन लर्निंगच्या दोन्ही प्रारूपांसाठी एकाच प्रकारानं त्रुटी मोजल्या आहेत.)
दिसताना ठीकठाक दिसतंय नाही हे प्रारूप? मला तरी ठीकच वाटेल.
आता पाळी मशीन लर्निंगची.
मशीन लर्निंगची मॉडेलं बनवण्यासाठी कुठल्याही प्रकारच्या गणिती स्वरूपाचा अंदाज करण्याची गरज नसते. मशीन लर्निंगमध्ये निरनिराळ्या प्रकारची अल्गोरिदम असतात. त्यातली पद्धत अशी की आपल्या सोयीनुसार एखादं निवडायचं आणि वापरायचं. प्रत्यक्षात निरनिराळी प्रारूपं वापरून कुठल्या प्रारूपात कमीतकमी त्रुटी आहे ते पाहतात; कधी त्या प्रारूपाचं स्पष्टीकरण देणं महत्त्वाचं असतं, तेव्हा निर्णयवृक्ष किंवा decision treesसारखी, त्यातल्यात्यात स्पष्टीकरण देता येतील अशी मॉडेलं निवडली जातात. इथे फक्त मुद्दा स्पष्ट करायचा आहे. त्यासाठी न्यूरल नेटवर्क, रँडम फॉरेस्ट किंवा आणखी कुठलंही अल्गोरिदम वापरून चालेल. पण ही झाडं लावणं आणि त्यांचं स्पष्टीकरण देणं सोपं असतं, तर तेच वापरलं आहे.
हे प्रारूप तयार करताना वरच्या सांख्यिकी प्रारूपासाठी जे विदाबिंदू वापरले तेच तीस बिंदू वापरले आहेत; म्हणजे जो x वापरला होता तोच आहे. शिवाय c म्हणजे intercept चालण्यासाठी वाढीव कॉलम वापरावा लागला होता. त्याची किंमत होती १. तीही तीच ठेवली आहे. विदा साधारण अशी दिसते.
| x | intercept | y |
|---|---|---|
| -4.948334 | 1 | -9.342172 |
| -4.244505 | 1 | -10.854786 |
| 4.890165 | 1 | 9.656738 |
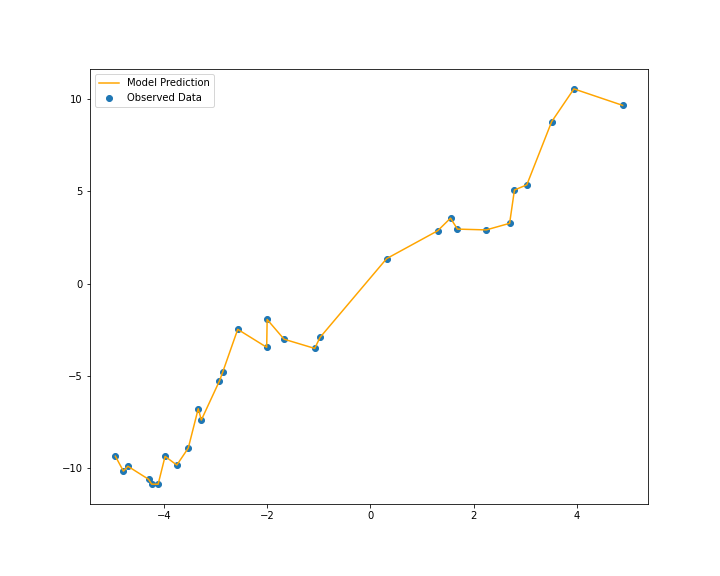
फक्त आलेख बघून ह्या दोन्हींपैकी कुठलं प्रारूप निवडाल? का?
मशीन लर्निंगच्या प्रारूपाची त्रुटी आहे - शून्य, ० . आता कुठलं प्रारूप निवडाल? का?
इथे दिलेल्या विदेच्या बाहेरचं, म्हणजे क्ष अक्षावरची किंमत -५ ते +५ ह्या सीमेच्या बरीच बाहेरची असेल, समजा १५ असेल तर ह्यांतलं कुठलं प्रारूप वापरणार? का?
प्रारूप बनवल्यानंतर, प्रत्यक्ष आयुष्यात अनेकदा अशा बऱ्याच प्रश्नांची उत्तरं द्यावी लागतात. त्याचं एकचएक उत्तर नसतं. संदर्भानुसार ते उत्तर बदलावं लागतं. 'ही विदा आणि हे प्रारूप वापरून ह्या प्रश्नाचं उत्तर देता येणार नाही'; हेसुद्धा कधीकधी योग्य उत्तर असतं.
(टिढीश, टिढीश, टिढीश) अर्थात क्रमशः
मशीन लर्निंगच्या प्रारूपाची
मशीन लर्निंगच्या प्रारूपाची त्रुटी आहे - शून्य, ० . आता कुठलं प्रारूप निवडाल? का
मशिन लर्निंग प्रारुपच निवडेन. कारण तृटी शून्य आहे. आदर्श आहे.
फक्त आलेख बघून ह्या दोन्हींपैकी कुठलं प्रारूप निवडाल? का?
ते झिगझॅग जरा किचकट फन्क्शन आहे. इन फॅक्ट ते चक्क अनप्रेडिक्टेबल आहे. तेव्हा आलेख पहाता, y=mx+c हे प्रेडिक्टेबल प्रारुप निवडेन.
इथे दिलेल्या विदेच्या बाहेरचं, म्हणजे क्ष अक्षावरची किंमत -५ ते +५ ह्या सीमेच्या बरीच बाहेरची असेल, समजा १५ असेल तर ह्यांतलं कुठलं प्रारूप वापरणार? का?
अर्थात सरळ रेषेचेच. कारण त्यामुळे तेवढ्या तृटीच्या मार्जिनमध्ये का होइना प्रेडिक्ट तर करता येतय.
>>>>>>>>>>>>>>>
>>>>>>>>>>>>>>>
मशीन लर्निंगच्या प्रारूपाची त्रुटी आहे - शून्य, ० . आता कुठलं प्रारूप निवडाल? का
फक्त आलेख बघून ह्या दोन्हींपैकी कुठलं प्रारूप निवडाल? का?
>>>>>>>>>>>>>>>>
माझा मुदलातला एक प्रश्न आहे मशीन लर्निंगच्या प्रारुपाविषयी:
वरच्या एम एल् आलेखात हे तीस पॉइन्ट सगळेच्या सगळे ट्रेनीन्ग डेटा आहेत का? (का मी काही मिस केलय?)
जर का हे सगळेच ट्रेनीन्ग पॉइन्ट्स आहेत हे ग्ृहीतक बरोबर असेल तर प्रश्नांची उत्तरं द्यायला अजून पाच दहा टेस्ट पॉइन्ट हवेत.
ते कोणत्या प्रारुपाला जवळ जातायत हे बघता येइल.
>>>>
क्ष अक्षावरची किंमत -५ ते +५ ह्या सीमेच्या बरीच बाहेरची असेल, समजा १५ असेल तर ह्यांतलं कुठलं प्रारूप वापरणार? का?
>>>>
ही विदा आणि हे प्रारूप वापरून ह्या प्रश्नाचं उत्तर देता येणार नाही
Variance and Bias -Trade off
Variance and Bias -Trade off is the important key concept in deciding any model. I guess the questions asked are leading up to that.
The Machine learning model has high variance and hence over fitting the training data. Although it has zero (less) training error, the error with test or validation data will be high.
( आता ह्याचं मराठीत भाषांतर करा. मला तांत्रिक, व्यावसायिक मराठी लिहिता येत नाही.) बाकी कोणतं मॉडेल आणि का ह्याचं उत्तर (बरेचदा) कोणता विदा आणि त्याचं (त्यापासून) नक्की काय करायचं आहे ह्यावर ठरेल नाही का ?
० त्रुटी म्हणजे १००% संशयास्पद
३० विदाबिंदू असणाऱ्या मॉडेलाची त्रुटी ० येत असेल तर मी ते नाकारेन. एकदा फक्त मनाची खात्री म्हणून असे आलेख काढून बघेन. त्यात सरळ रेघ बसवायच्या जागी असा वेडावाकडा आकार असेल तर ते नाकारेन.
कारण - त्रुटी ० म्हणजे overfitting. मॉडेलनं असलेली सगळी विदा घोकून काढली आहे. त्यात काही शहाणपणा नाही. त्यामुळे आहे त्या -५ ते ५ ह्या रेंजमध्येही नवा काही बिंदू आला तर मॉडेल गंडणार ह्याची मला खात्री आहे.
दुसरं कारण - वेडेवाकड्या आकारांचं काहीही स्पष्टीकरण देता येत नाही. बहुतेकदा मॉडेलांचे अर्थ लावायचे असतात; सरळ रेघेचा अर्थ लावता येतो; ह्या वेड्यावाकड्या रेघेचा अर्थ लावता येत नाही. म्हणूनही मी ते नाकारेन. ह्याला अपवाद असतात - computer vision छापाचे. पण त्याचे आलेख अशा प्रकारचे काढले जात नाहीत.
दुसरं कारण - वेडेवाकड्या
दुसरं कारण - वेडेवाकड्या आकारांचं काहीही स्पष्टीकरण देता येत नाही. बहुतेकदा मॉडेलांचे अर्थ लावायचे असतात; सरळ रेघेचा अर्थ लावता येतो; ह्या वेड्यावाकड्या रेघेचा अर्थ लावता येत नाही. म्हणूनही मी ते नाकारेन.
वहीच मै भी बोली!! :)
____________
कारण - त्रुटी ० म्हणजे overfitting. मॉडेलनं असलेली सगळी विदा घोकून काढली आहे. त्यात काही शहाणपणा नाही.
ह्म्म्म!!??
rolling average
शेअर बाजारासाठी लोक ह्या गोष्टी वापरतात, असं मी rolling average शिकताना यूट्यूबवर बघितलं होतं. पायथन मला वापरायला सोपी वाटते. पण मला त्याचा काडीचाही अनुभव नाही. माझ्याकडे पुरेसं गुगलग्यानही नाही.
विकेण्डला नवा भाग लिहिण्याआधी आहे तो कोडही साफ करून गिटहबवर चढवेन. त्याचीही लिंक देईन. कुणाला त्याच्याशी खेळायचं असेल तर तेही करता येईल.
पायथनच
मी पायथनच वापरते मात्र टेन्सरफ्लो, पायटॉर्च वगैरे लायब्रऱ्या मी वापरलेल्या नाहीत. कदाचित लवकरच PyMC3 वापरण्याची वेळ येईल, त्यात पायटॉर्च वापरलं आहे. पण माझा संबंध त्याच्याशी येणार नाही. सध्या माझा संबंध बहुतेकदा SQLAlchemy आणि scikit-learn एवढाच मर्यादित असतो. मी सध्या ज्यावर काम करत्ये, ती मॉडेलं फार गुंतागुंतीची नाहीत. आहेत ती मॉडेलंही अत्यंत वाईटच आहेत, हे आम्हांला माहीत आहे. पण तो अगदी निराळा विषय झाला.
मला म्हणायचं होतं, मी पायथनच वापरते; पण सुधीर ह्यांना ज्या पद्धतीनं वापर करायचा आहे, ते मला माहीत नाही. मला त्या विषयातले तपशील अजिबातच माहीत नाहीत.
मशिन लर्निग आणि सांख्यिकी
मला याचा उपयोग नक्की कसा होऊ शकेल ते बघायचे आहे. कालच हे युट्यूब चॅनल सापडले... वर विचारलेल्या प्रश्नांची उत्तरे मिळाली.
नाहीतर सांख्यिकी मध्ये पण स्पुरिअस कोरिलेशन शोधून काही फायदा होत नाही. उदा. मागच्या आठवड्यात हे पाहिले. मशिन लर्निंग मला असले काही फॅन्सी शोधून नाही देणार ही अपेक्षा.
समजा मला २% ऑपरेटींग मार्जिन वाढण्याचे शक्यता वाटते. तर नवीन फॉरवर्ड एंटरप्राईज व्हॅल्यू टू सेल्स प्रोजेक्ट करायचे असेल. वा समजा एखाद कंपनीचा सेल्स वा मार्जिन कुठल्या तरी एका फॅक्टर बरोबर हायली कोरिलेटेड असेल. आणि जर तुम्हाला सेल्स / मार्जिन पर्यायाने ईपीएस खूप चांगल्या पद्धतीने प्रेडीक्ट करता येतील. पण तो फॅक्टर तर आपल्यालाच शोधावा लागतो. सांख्यिकी तुम्हाला मदत करते की ते कोरिलेशन कितपत चांगले आहे.
मशिन लर्निग हे सांख्यिकी पेक्षा वेगळे कसे आणि कुठे आहे ते जाणून घ्यायचे आहे.
बाकी फायनान्स मध्ये एक्सेल झिंदाबाद पण सिएफए इंडियाच्या या एका वेबेनार मध्ये यांनी पायथन वापरून काही रुटीन टास्कचे ऑटेमेशन कसे केले आहे ते छान सांगितले आहे.
ती जबाबदारी आपलीच.
मशीन लर्निंग आपण होऊन अशी नळ्यासोबत गाड्याची यात्रा काढत नाही; ते आपण जो काही कच्चा माल मॉडेलला देऊ, मॉडेल त्यातूनच परस्परसंबंध लावतं. आपण अशी काहीच्या काही विदा दिली नाही, तर मशीन लर्निंग त्यांचा संबंध लावणार नाही. पण आपलं आकलन चूक असेल, म्हणजे परभणीतल्या पावसामुळे शेअर बाजार वरखाली होतो, हे खरं असेल तर मॉडेल ते शोधून काढेल. हे खरं नसेल तर काही प्रकारची मॉडेलं ते बाजूला करू शकतात.
मशीन लर्निंगमध्ये अडचण अशी असते की, कार्यकारणभाव सांगता येत नाही. म्हणजे काल परभणीत सव्वा मिमी पाऊस पडला म्हणून आज शेअर बाजार १०० पॉइंट्सनी वर गेला, असं सांगता येत नाही. फार तर परभणीतल्या पावसामुळे शेअर इंडेक्स वरखाली होतो, एवढंच म्हणता येतं. सांख्यिकीमध्ये अशी विधानं करता येतात.
(मला ह्या विकेण्डला नवा भाग लिहायचा होता; पण ऐसीबाह्य लेखनामुळे ते जमलेलं नाही. आठवडाभरात लिहायचा प्रयत्न करते.)
वाचते आहे.
जरा मोठे भाग टाक.